 Pekka Helenius
9cb367222d
Pekka Helenius
9cb367222d
|
4 years ago | |
|---|---|---|
| code | 4 years ago | |
| screenshots | 4 years ago | |
| README.md | 4 years ago | |
| sample_dataset.json | 4 years ago | |
| url-analysis-report.pdf | 4 years ago | |
README.md
URL Analyzer
URL data analyzer and extractor. Detect malicious signs and other useful data associated with URLs.
About
This program extract various website information based on URL addresses. This data can be used to analyze maliciousness of the given URL.
Features
NOTE: See sample JSON data: Get file
To summarize, the program does the following procedures for listed URLs:
-
Gets domain registrar
-
Gets webpage title and automatically compares it to the domain registrar name
-
Gets initial and final destination of a given URL
- Analyzes whether final destination domain is same than the initial one
-
Gets URL redirects and HTTP response status codes
-
Fetches WHOIS data
- Gets domain timestamps such as creation, update and expire days
- Exact days & days relative to the current day
- Gets domain timestamps such as creation, update and expire days
-
Gets content and number of iframes (for detecting possible XSS; Cross-Site Scripting)
-
Gets URL references on a webpage
- Local domain referrals
- External URL referrals
- Multidot URLs (ones with
../in the URL path)- Gets domain registrars for each URL
Requirements
Python 3
Python 3 BeautifulSoup4 python-beautifulsoup4
Python 3 whois <= 0.7.3 python-whois; PyPI
Python 3 JSON Schema python-jsonschema
Python 3 Numpy python-numpy
Python 3 matplotlib python-matplotlib
NOTE: Some Linux distributions may use python3 executable instead of python for Python 3.
Other requirements
- Jupyter (recommended)
- Working DNS name resolution
- Internet connection
Code
Documents
Report example
-
URL domain registrar variation analysis: Get report- Generated with command
jupyter nbconvert url-analyzer.ipynb --template hidecode --to pdf
- Generated with command
Screenshots
The following screenshots are generated with matplotlib
Domains associated with HTML URL data
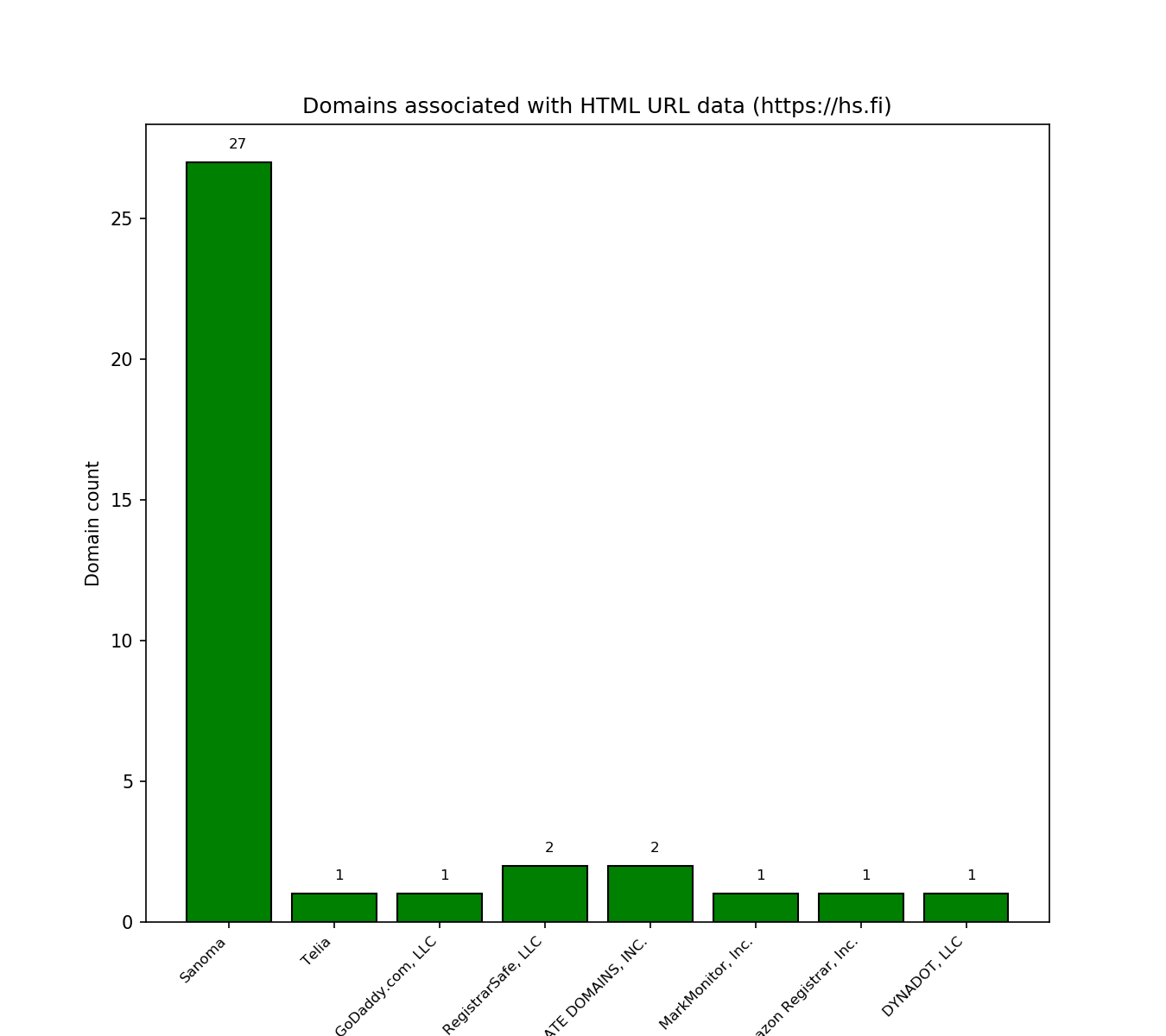
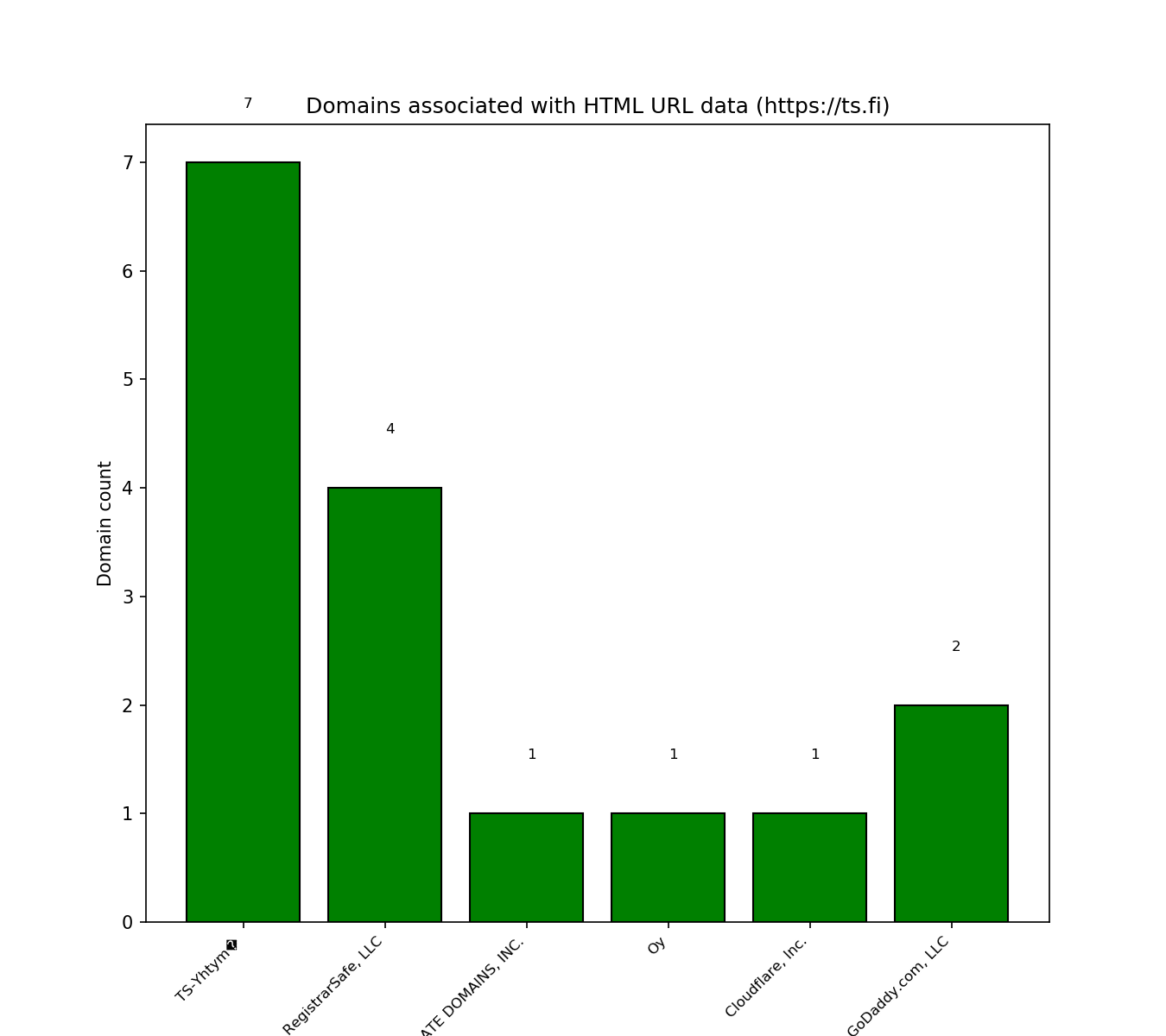
Purpose - WHOIS query lookup:
- Phishing campaigns register domains of websites from the same registrar
Other analysis would reveal more
Other analysis may give better insights such as:
-
Initial and final URL:
- "Even if victim realizes he/she is visiting phishing website, he/she will be likely to report the randomly-generated URL of the visited website, and not that of the redirecting one, which makes blacklisting unable to stop the scam"
- Phishing URLs may use multiple redirections to avoid blacklist detection
-
Domain timestamps:
- Domains bought for short period of time (i.e. only one year) to avoid blacklisting
- Domains are created/updated just before URL creation
-
Domain name & local URL usage consistency
-
Domain name registration:
-
"Legitimate websites are likely to register a domain name reflecting the brand or the service they represent."
-
Domain name length:
- In phishing websites, URL tends to be much longer than legitimate websites. However, domains themselves tend to be much shorter (without TLD)
-
URL analysis
- Phishing URLs often contain more number of dots and subdomains than legitimate URLs
- "Researchers have observed that more than half of the phishing URLs are shortened to obfuscate the target URL and to hide malignant intentions rather than to gain character space"
-
Robots.txt analysis:
- Legitimate robots.txt redirects bots to a legitimate domain rather than to the original phishing domain
HTML data keyterms identification
- Analysis of
- Starting URL
- Landing URL
- title
- text content
- copyright marks
- number of
iframes andinputfields - Reference links (
href,src, etc.)
Known bugs issues and missing features
-
Non-UTF-8 character decoding not implemented
-
If multiple JSON data files exist, a wrong JSON data file is likely selected
-
Get URLs and other parameters from command line and/or associated
.conffile -
More data visualization and compherensive analysis
-
Null data may be generated in some cases
-
Add (unit) tests
-
Improve modularity of the codebase
License
N/A