SQL database planning, development & usage
SQL database planning, development & usage
Excel spreadsheet data processing is a familiar approach for everyone to handle local client data sets. However, for server-side data handing, centralized SQL databases are used. More modern NoSQL techniques are even better for big data due to horizontal server scaling possibilities.
In this post, I cover a basic SQL database lifecycle from client requirements specification to detailed database use and data analytics, using a fictional game tournament service as an example platform.
NOTE: Database and all content of this post is also available as a Git repository.
Table of Contents
Introduction
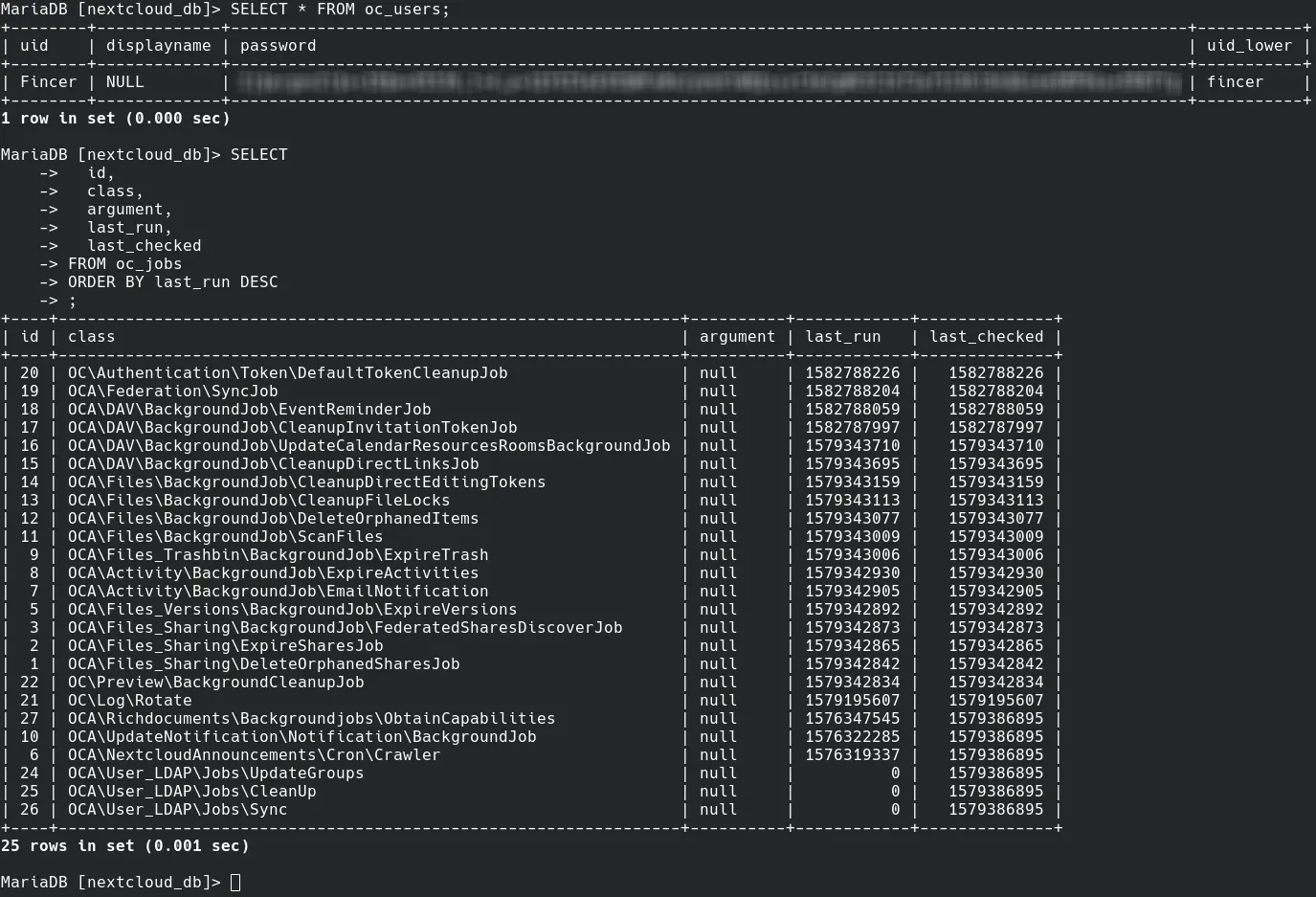
Until this day, I have got familiar with SQL databases mostly via examining and altering them with indirect methods, such as during CloudStack or Nextcloud server configuration operations or opening random datasets used by various software. I found out that planning, testing and using your own SQL database for software adaptations is far more fascinating.
In this post, I do not cover fundamental principles of SQL database planning, SQL query language tutorials or any alike. There are many good online tutorials and countless books which guide you very well to the subject.
Covered subjects
This database post demonstrates database life cycle which starts from requirement specification and ends up to several use cases and data insights. The use cases are developed with pure SQL query techniques and do not use external codes (such as Java JDBC, Python SQL or PHP). The produced database, however, can be merged in an interactive application code.
Database requirements specification
The following vague, initial database requirements specification has been received by database planners:
Planning
Core objects and their attributes
Core objects and targeted user groups for the new tournament database are game organizers, playing teams and their players and bettors with the following needs:
Game organizers
- Need: Game organizers want organize various game tournaments and manage related information. Organizers also control and operate betting functions.
Teams and their players
- Need: Teams and their players want participate to organized and planned game tournaments. Teams want also manage their internal player ranking information.
Bettors
- Need: Bettors want bet for various participating teams in a game tournament via a web-based interface. They are able to sign up and create an unique, distinguishable account with necessity to give valid bank account information. Otherwise, no detailed or private information is required by the tournament platform.
A private company will own the tournament database. The database is administrated and developed by various employees with different permissions and access levels. Head of the company and financial department have a lot of interests to data analysis based on gained tournament data, and statistical possibilities in general.
Excluded content
Planned database excludes following secondary information:
Space/Club booking fee: the database will not include detailed data table for space owner, thus fee information is excluded, outlining the project.
Payment confirmation: the database will not have this information. External database combined with sophisticated application programming is preferred.
Payroll and work-related information: the database will not consider deeper relationships between employers and their employees, including payrolls and collective agreements. Payroll system or any system alike is excluded, outling the project. The database will not include information related to employment periods.
Sensitive personal information: the database excludes unique identity information of players, organizers and bettors, like personal identification number or birthday. The database will not hold information about person's sex or any other profiled information.
Class diagram

Data dictionary (class diagram)
Relation diagrams


Data dictionary (3NF)
Normalization
The tournament database has four commonly linked, identifiable objects:
Event: There is an event which defines organizing a game tournament and related attributes. Each event has ranking information of contributed teams.
Team: There are teams in a tournament. The database must have detailed information (attributes) about each team. Each team has players.
Organizer: A tournament is organized by a game organizer so the database must have detailed information (attributes) about each of them. Organizer has employees.
Betting: Betting is possible for fans in tournaments.
Therefore, four new tables can be formed: EVENT, TEAM, ORGANIZER, BETTING
0 Normal Form
Even now we know that team, organizer and betting are all related to event, so we can create a reasonable relationship between EVENT table and the rest of the tables. We still haven't defined any actual attributes but by following requirement specification and extending our thinking, we can come up with the following definition:
This table structure, however, has major issues and duplicate attributes so it is reasonable to normalize the 0NF database form and continue all way to 3NF form, step by step.
1 Normal Form
Requirement and goal:
1) Dividing multivalued attributes (attributes which are repeated):
2) Organizing structural attributes (dividable attributes):
Rename attribute [team] to [team_name] in EVENT table.
Trivial functional dependencies:
event_id -> event_name, event_starttime, event_endtime, event_fee, event_extrainfo, event_city, event_street, event_housenumber, organizer, clubroom, reservation, team_name, team_status, team_rank, team_IBAN
team_id -> event_id, team_name, team_email, team_phone, team_city, team_street, team_housenumber, team_rank_global, player_firstname, player_lastname, player_rank
org_id` -> event_id, org_name, org_email, org_phone, org_city, org_street, org_housenumber, employee_firstname, employee_lastname`
betting_id -> event_id, bettor_firstname, bettor_lastname, bettor_team_guess, bettor_rank_guess, bettor_multiplier, bettor_initmoney, bettor_IBAN, bettor_betstatus
Tournament SQL database, 1NF
2 Normal Form
Requirement and goal: all attributes depend on the whole primary key.
Table relations
The current database structure lacks of player attribute information, therefore we add new table PLAYER. Player is dependent on team which is why we add new reference key attribute [team_id] into PLAYER table. Let's form the following functional dependency:
player_id -> team_id, player_firstname, player_lastname, player_email, player_phone, player_city, player_street, player_housenumber, player_rank
We shall remove attributes [player_firstname], [player_lastname] and [player_rank] from TEAM table because these attributes have already be defined in PLAYER table. Therefore, we shall modify structure of TEAM table and form a new functional dependency for its attributes as follows:
team_id -> team_name, team_email, team_phone, team_city, team_street, team_housenumber, team_IBAN, team_rank_global
Team participates an game tournament event so we need to create relationship between TEAM and EVENT tables. To achieve this goal, we simply add a new reference key attribute [event_id] into TEAM table. Therefore, new functional dependency for TEAM table is:
team_id -> event_id, team_name, team_email, team_phone, team_city, team_street, team_housenumber, team_IBAN, team_rank_global
ORGANIZER and EMPLOYEE
The current database lacks of organization employee attribute information so we add new table ORG_EMPLOYEE and rename ORGANIZER table to ORGANIZER_ORG. Additionally, we shall rename the primary key of ORGANIZER_ORG table from [org_id] to [organizer_org_id]. New functional dependency describing the new ORG_EMPLOYEE table is:
employee_id -> employee_firstname, employee_lastname, employee_email, employee_phone, employee_city, employee_street, employee_housenumber
Because we have a table containing employee information, we shall delete employee information from ORGANIZER_ORG table. Additionally, we add new reference key attribute [event_id] for ORGANIZER_ORG table because organizer sets up new events. As a conclusion, we end up having the following functional reference for ORGANIZER_ORG table:
organizer_org_id -> event_id, org_name, org_email, org_phone, org_city, org_street, org_housenumber
As an employee works in an organization, it therefore has dependency on the particular organizer. We add new reference key attribute [organizer_org_id] into ORG_EMPLOYEE table. Functional dependency is:
employee_id -> organizer_org_id, employee_firstname, employee_lastname, employee_email, employee_phone, employee_city, employee_street, employee_housenumber
Because the new ORGANIZER_ORG table refers to an event and because the new TEAM table has also this reference, we can remove attribute [organizer] from EVENT table.
TEAM_STATUS
Because we have formed an independent table for teams, we can delete team-related attributes from EVENT table. It is reasonable to form a new table TEAM_STATUS which hold information regarding team statuses and in-tournament rankings. As a whole, we can describe functional dependency for EVENT table as follows:
event_id -> event_name, event_starttime, event_endtime, event_fee, event_extrainfo, event_city, event_street, event_housenumber, clubroom, reservation
New primary key (pair) [team_id, event_id] will be formed for TEAM_STATUS table. We shall add attributes [team_status] and [team_rank] and make their dependant on this new primary key. Expressed as a functional dependency:
team_id, event_id -> team_status, team_rank
BETTING and BETTOR
It is essential to understand that bettor attributes in BETTING table do not describe betting event itself, therefore those attributes form an independent logical set separated from betting. Therefore, we shall create new table BETTOR. Using only first and last name for a bettor does not meet requirements of describing bettor as an unique, identifiable object which is why we need to add more bettor attributes. We assume bettor to actually be an user account so bettor shall have encrypted password attribute, as well. Functional dependency for bettor could be:
bettor_id -> bettor_firstname, bettor_lastname, bettor_email, bettor_phone, bettor_IBAN, bettor_password
Value of new, unique user account for bettor is described by the primary key [bettor_id].
Betting is clearly dependent on tournament events, teams and bettors: we have a team playing in an event, and a team to which a bettor can bet on. Therefore, we can actually have a new primary key for BETTING table consisting of multiple attributes. Expressed as a functional dependency:
bettor_id, event_id, team_id -> team_rank_guess, multiplier, initmoney, betstatus
It's worth noting that we have deleted attribute [bettor_team_guess] and replaced it with partial primary key attribute [team_id] which is simultaneosly a reference key to attribute [team_id] of TEAM table. This reference key structure ensures BETTING table consistency related to the rest of the formed database and enforces that a referred team must exist in the database. All primary key attributes in BETTING table are actually reference keys. Therefore, it's quite irrelevant to keep attribute [betting_id] anymore in the BETTING table.
Naming of attribute [bettor_rank_guess] is rationalized and is known as [team_rank_guess] from this moment on. The attribute expresses bettor's guess for team ranking in a betting event. Another reason for renaming is that BETTING table does not directly contain bettor information anymore. Therefore, attribute [bettor_multiplier] is known simply as [multiplier] and [bettor_initmoney] as [initmoney]. Attribute [betstatus] is linked, not to bettors, but to bettings which is why it's included in BETTING table.
Tournament SQL database, 2NF
3 Normal Form
Requirement and goal: all attributes depend only on the primary key.
Table relations
COUNTRY, CITY and location information
We can see duplicate contact and location information left on the previous normalization phase which is why we shall rationalize and organize the database table structure even more. As we talk about an international database we need to keep in mind that contact or location information is not tied to a single country. This is why we shall form two new tables: COUNTRY and CITY. All location information, excluding still somewhat unique street and house number related attributes, should be moved into the new tables.
CITY and COUNTRY tables have a relationship between each other because cities are tied to countries, obviously. Therefore, we introduce new functional dependency:
country_id -> country_name
Since the database is international in nature, we assume that it will contain a lot of postal code and city information. Due to large amount of postal codes, we can't assume that they all are unique in all possible cases worldwide. Since city name can't either be used to determine the uniqueness of a database row in CITY table, we can conclude that only way to get certain uniqueness of CITY table data values is to form a new primary key pair which consists of [postalcode] and [country_id] attributes, and holds city name information. Expressed as a functional dependency, we declare the following:
postalcode, country_id -> city_name
As we have majorly altered the database structure due to introduced contact/location information changes, we reform the database structure and write the following functional dependencies for other database tables:
team_id -> team_name, team_email, team_phone, team_postalcode, team_street, team_housenumber, team_IBAN, team_rank_global
player_id -> team_id, player_firstname, player_lastname, player_email, player_phone, player_postalcode, player_street, player_housenumber, player_rank
organizer_org_id -> event_id, org_name, org_email, org_phone, org_postalcode, org_street, org_housenumber
employee_id -> organizer_org_id, employee_firstname, employee_lastname, employee_email, employee_phone, employee_postalcode, employee_street, employee_housenumber
Bettors are not assumed to have requirement of adding detailed contact or location information.
CLUBROOM, RESERVATION and ARRANGEMENT
In 2NF phase, we expressed the following functional dependency for EVENT table:
event_id -> event_name, event_starttime, event_endtime, event_fee, event_extrainfo, event_city, event_street, event_housenumber, organizer_id, clubroom, reservation
In this dependency, we can think place of a tournament and the tournament itself as independent objects. Remember the requirement specification: tournaments do not require physical location and can be organized online. Additionally, we don't really want to fill our database with NULL values. Therefore, we split the existing EVENT table forming a new CLUBROOM table. EVENT table is renamed to GAME_EVENT to make it more distinguishable.
Because clubroom has a physical location, we shall add location attributes to the new table, and in the same time, remove this information from GAME_EVENT table.
Therefore, functional dependency for the new CLUBROOM table is:
clubroom_id -> clubroom_name, clubroom_postalcode, clubroom_street, clubroom_housenumber
We still need to have a reference key for clubrooms in GAME_EVENT table. Note that we have removed attributes [organizer_id], [clubroom], [reservation]. Removal of attribute [organizer_id] is explained below. In the other hand, the latter two attributes are directly related to clubrooms themselves. In the end, we have a new functional reference for GAME_EVENT table:
event_id -> clubroom_id, event_name, event_starttime, event_endtime, event_fee, event_extrainfo
It is very assumable that an organizer reserves a clubroom for a gaming tournament and the reservation has unique time stamp. Therefore, we can form a new functional dependency. Removed attribute [organizer_id] and new attribute [clubroom_id] form a new primary key pair, describing value of a new attribute [reservation_time]:
organizer_org_id, clubroom_id -> reservation_time
Let's create a new table RESERVATION for this functional dependency.
Additionally to a space reservation, an organizer arranges a tournament event. Therefore, organizer and event have a relationship. Since event and organizer are already described in their respective tables, it is recommended to form a new joining table between these two subjects. We create a new joining table ARRANGEMENT which describes an event arrangement by an organizer. The table consists of two attributes, and a single primary key, desribed as follows:
{organizer_org_id, event_id}
PLAYER_RANK and TEAM_RANK_GLOBAL
Because player rank in a team is tied both to player and event, we shall add new table PLAYER_RANK. The primary key of the new table is [player_id, team_id] and has attribute [player_rank] which we concurrently remove from PLAYER table. PLAYER_RANK table attributes form the following functional dependency:
player_id, team_id -> player_rank
We want simple database table to describe team rankings in global scale. Because team global rankings are tied to team unique id, we can create a new joining table TEAM_RANK_GLOBAL with the following primary key:
{team_rank_global, team_id}
Due to the new table, we shall remove attribute [team_rank_global] from TEAM table. Alternative, we can keep the attribute in TEAM table but this decision will have unnecessary team data overhead in SQL queries. Forming a new table instead optimizes possible SQL queries a little bit.
International bank accounts
Not all international banks use IBAN bank account format. Many financial systems rely to alternative SWIFT standard. SWIFT account consist of two separate parts: bank id and linked account number. Because our goal is to develop a flexible database for international use, we must have support both for IBAN and SWIFT systems. Therefore, we add two new attributes [SWIFT_bank] and [SWIFT_number] both in TEAM and BETTOR tables.
Tournament SQL database, 3NF
Permissions
Concept: User groups & permissions based on specification
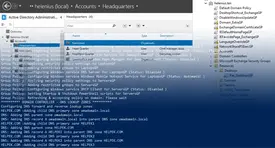
NOTE: The following permission plan is not realistic and can't be directly adapted to a real database design. The plan relies on known database user roles which are actual attributes in the database. In real database implementation and application development, database is managed by a separate user in a database server, and application code determines which user in this system should have (full) privileges to the database in a database server for data processing operations. Database users, as represented in a web form, for instance, are actually unique attribute values read by the database system user. Database user permission logic is, therefore, handled by the application code. An example of database system user connection between application configuration and an actual database is shown in the picture below.
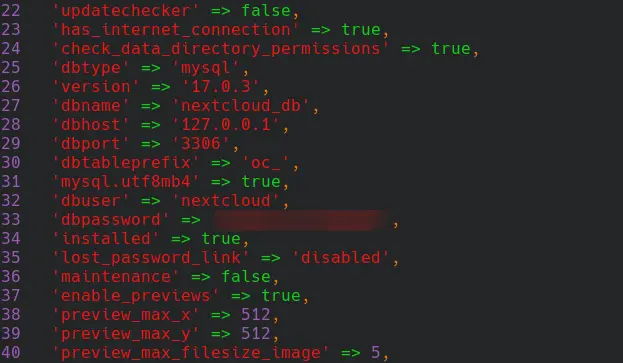
dbuser (database user) and dbname (database name) which are used by the cloud application to access the described database in the determined database server. Nextcloud users are attributes in the database. Permission logic and shown user information are consisted of database attribute values, additional data files in the server (personal files, for instance) and handled by Nextcloud PHP code. Database is just a place which holds parts of this information.In the following simplified example, we still assume that permissions related to user groups of the tournament database are actually handled by the database server. In this imagined case, roles and table-specific permissions for different user groups could be:
In a real case, these restrictions are used to fine-tune permissions of the database server user, configured directly in the server by a privileged administrator. Another note worth mentioning is usage of unique table views for various users, which are excluded. In application development, views can be used to refine database table data in database server level and fine-tune permissions to access, use and modify specific data. Views are usually used to enchance security policy in a database server.
Concept: User groups, database server level
Instead of relying known user roles, a better approach would be determining actual database server users with various permissions. Relational Database Management System (RDBMS) such as MySQL server could have database users as follows:
| User | Permissions |
|---|---|
| root | the highest privileges; high protection |
| superadmin | access to the most DB operations |
| defaultadmin | access to many DB operations |
| helpdesk | access to a limited pool of DB operations |
| tournament_user | tournament web application user having various permissions depending on DB operations and web-user management |
Each performed operation writes a new log entry in the database server as configured, for instance, in the database server configuration files.
Since working application logic may implement complex data processing techniques, it is not recommended to alter database values manually. Therefore, developing the database following four SQL DB integrity constraints is required. Manual interventions are usually allowed only to the most high level admins (superadmin) which can control server operations as whole (such as configuring, starting and stopping servers for maintenance, and managing the most relevant IT infrastructure). Usually these admins shall have sudo (Unix) or SYSTEM/ADMINISTRATOR (Windows) permissions on the target server systems. RDBMS root user should never be used in maintenance operations, only when setting up a new database server. However, root access should still be possible, and only granted for the most trusted top level administrators, depending on company security policy.
Lower admins (defaultadmin) may have wide but limited access to target databases. Helpdesk users could access the database non-sensitive data entries in limited scale and only perform SELECT queries.
SQL queries for permissions
Development environment
The tournament database was developed in MariaDB server environment. SSH tunneled remote connection was established to the server. Server basic information is as follows:
Name: mariadb
Version: 10.3.14
Operating System: Arch Linux
Remote connection: yes
Encrypted connection: yes
Limited access: yes
Owner: fjordtek.com (Pekka Helenius)
Database server had a chrooted Unix user for SQL server access. The server network environment was an isolated DMZ zone.
SQL database
This section has necessary SQL queries to establish the described database in MySQL-based server. The database uses normal form 3. Added data values are mostly fictional and computer-generated, and thus do not contain any real personal data.
Creating database structure: CREATE queries
Inserting initial data: INSERT queries
Database usage
This section describes basic database use cases in different situations. Scenarios are based on the existing database data, the requirement specification and in imagenary events that may occur during database lifetime.
SELECT queries
Task 1 - Finding players with missing contact information
Task 2 - Unused city data
Task 3 - Unused country data
Task 4 - Data insights: better country statistics
Task 5 - Data insights: The most popular team among bettors
Task 6 - Data insights: Average team rankings
Task 7 - Data insights: profits and expenses
Task 8 - Data insights: country distributions of teams, players and bettors
INSERT queries
Task 9 - Inexperienced database guy
Task 10 - New game event
Task 11 - New team and team members
Task 12 - New employee
Task 13 - Participating bettors
UPDATE queries
Task 14 - Player contact information
Task 15 - Updating game event information
Task 16 - Fix errors in current data
Task 17 - Employee contact information
ALTER queries
Task 18 - Adding team license status information
Task 19 - Additional information fields for bettors
Task 20 - Adding A3 country codes
DELETE queries
Task 21 - Cancelled game event
Task 22 - Deleting banned team
Task 23 - Bankrupted game organizer
Task 24 - Cheating bettor
Task 25 - Inactive players
Task 26 - Unused city data
Task 27 - Unused country data
SQL database - deletion
DELETE queries
DROP queries
Conclusions
I worked out the project independently taking full responsibility of the database design, testing, task descriptions, performed queries, normalization phases and user permissions planning. The project was interesting. Further development would require program integration but it was excluded on purpose, and the focus was strictly on the database.
The developed tournament database is quite static and seriously lacks dynamic programming design. For instance, these limitations really hit when I planned user permission policy, and the policy should be fully re-evaluated.
Task descriptions are fictional, although I wanted to think about possible scenarios which could occur during the database life cycle. Some queries are quite simple, and other require bit more complex solutions to get desired results or relevant statistics. I kept one key principle in mind during database design phase: database structure must hold on even when having more complex task layouts. Test passed, time to move on.